在软件开发过程中,乱码是一个常见且令人头疼的问题。无论是前端展示、后端数据处理,还是数据库存储,都可能遭遇字符编码不一致导致的乱码现象。本文将从乱码产生的原因、常见场景及解决方案等方面进行系统阐述。
一、乱码问题的根源
乱码本质上是字符编码与解码方式不匹配造成的。当系统使用一种编码方式存储数据,却用另一种编码方式解析时,就会出现乱码。常见编码标准包括UTF-8、GBK、ISO-8859-1等,其中UTF-8因其兼容性和国际通用性成为当前主流选择。
二、常见乱码场景
- 前端显示乱码:网页字符编码声明与实际编码不一致,导致浏览器解析错误
- 数据传输乱码:HTTP请求/响应未正确设置字符编码,特别是在表单提交和AJAX通信中
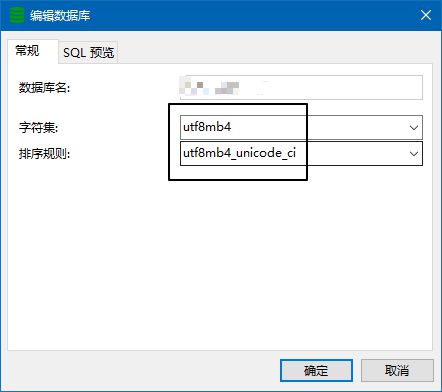
- 数据库存储乱码:数据库、数据表和连接字符集设置不统一
- 文件读写乱码:读取或写入文件时未指定正确编码格式
- 系统间交互乱码:不同系统、服务间数据传输时编码标准不一致
三、解决方案与实践建议
- 统一编码标准:项目初期就确定使用UTF-8编码,并在所有环节保持一致
- 明确声明编码:在HTML头部添加,在HTTP头中设置Content-Type
- 数据库配置:确保数据库、数据表、连接字符串都使用统一的字符集
- 代码规范:在文件读写、网络传输等操作中显式指定编码格式
- 测试验证:特别关注包含中文、特殊符号等边界情况的测试
四、调试与排查技巧
当遇到乱码问题时,可以按以下步骤排查:
- 确认数据源编码
- 检查传输过程中的编码转换
- 验证接收端的解码方式
- 使用编码转换工具进行测试
通过建立统一的编码规范,加强团队间的协作沟通,并辅以适当的自动化检测工具,能够有效预防和解决软件开发中的乱码问题,提升软件质量和用户体验。